Capturing Rules
If you’re testing a web application or API, there will be times when the application returns uniquely generated data in a response, and you’ll need to extract the value and reuse it later in this script. You can capture and reuse values with a capturing rule, or capturer for short.
When to Use Capturing
A few examples of when capturing might be necessary include:
- A unique session ID that the web application sets in the URL or Location header
- A CSRF token (like many web frameworks use to prevent cross-site request forgery)
- A dynamically generated ID for a newly created resource
- An order confirmation number, receipt, or transaction ID
Since these values are generated on the server, they’ll likely be different every time your script runs, so you have no way of knowing ahead of time what values may be returned. With a capturing rule, you can parse and extract them dynamically, and store them in a variable to use later.
Capturing rules are only supported for protocol scripts. If you need similar functionality in a browser script, you can implement it in a code block.
Creating a Capturer
To create a capturing rule, click on Add… in an HTTP step to expand the step context menu.
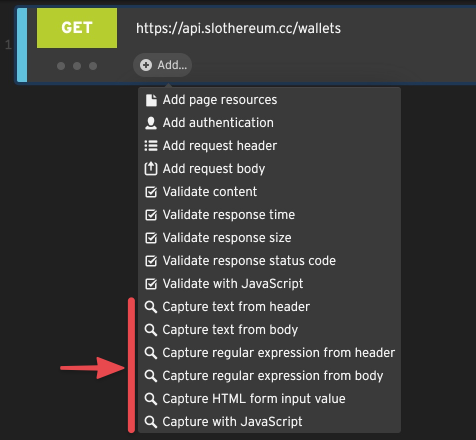
Loadster has several types of capturing rules: text capturers, regular expression capturers, and JavaScript capturers. A capturing rule can scan the entire response body, or a specific response header. It then stores the captured value in a variable that you can use later in your script.
Text Capturers
Text capturers are the simplest type of capturer. They scan for a string nested between two boundary strings that you specify. Think of these strings as left and right boundaries if you like… or possibly a sandwich.
Example: Capturing from the Location header
Many web applications make use of HTTP 301 or 302 redirects. When your application returns a status of 301 or 302, it also
provides a redirect location in the Location header. The web browser (or any HTTP client) is supposed to proceed to
the URL specified in the Location header, thus completing the redirect.
To capture text from a response header such as the Location header, select the Capture text from header option.
Then specify a destination variable name, the name of the header to be scanned, and optionally a left and right
text boundary.
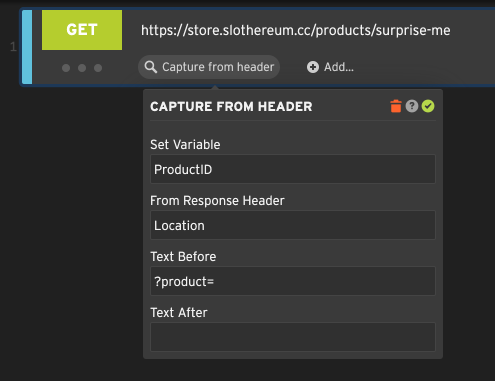
In this contrived example, the store is going to redirect us to a random product (feeling lucky?), and we’ll capture
its ID to a variable called ProductID that we can reference later in the script as ${ProductID}.
Example: Capturing a CSRF token in the response body
Many web applications use dynamic CSRF tokens to protect web forms from cross-site request forgery. Every time you load a web form it contains a random token that only the server knows, so if a POST request comes in the server can verify that it was from your form and not some malicious script piggybacking on your session.
In a Loadster script, submitting a web form with a CSRF token will fail unless we first capture the CSRF token and submit it with the form. Since the CSRF token changes every time, we’ll create a rule to capture it from the web form into a variable, and then include that variable as a parameter in the next step when we submit the form.
To capture text from the response body, select Capture text from body. Specify a destination variable name and a left and right text boundary.
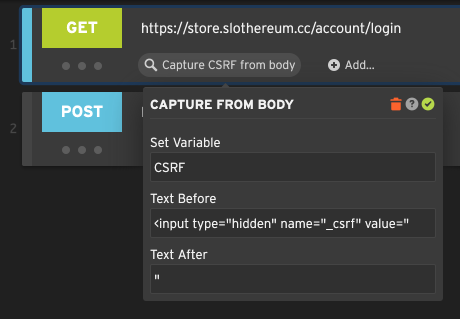
Here we are capturing the value of a hidden form field called _csrf and storing it in a variable called CSRF.
The following POST step will submit this as _csrf=${CSRF} so that the server accepts the form submission.
Regular Expression Capturers
If the left and right boundaries are too simplistic, you can capture variables using regular expressions.
A regular expression (or regex) is a sequence of characters that forms a search pattern. They are used in many programming languages for pattern matching and string manipulation. Loadster’s regular expressions are basically JavaScript-style regular expressions.
To create a regular expression capturer in Loadster, click on Add… within the desired HTTP step. Then provide a destination variable name, a regular expression with at least one capturing group (denoted by parentheses), and an output expression. As with other types of capturers, you can choose to apply the regular expression to the entire response body, or a specific header.
Example: Capturing an order number after placing an order
Let’s say we’re scripting a shopping cart checkout flow, and the user has just submitted an order. A unique order number is generated by the site, and we need to capture it to use later in our script.
To capture with a regular expression from the response body, select the Capture regular expression from body option.
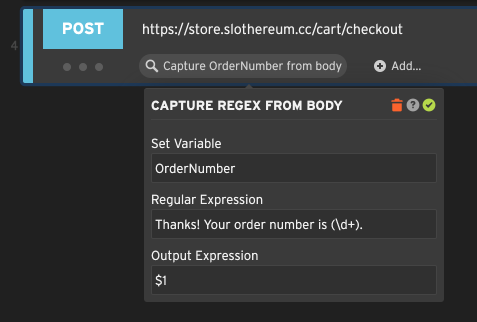
In this example we are capturing a variable called OrderNumber, which we’ll reference later in the script as
${OrderNumber}. The regular expression will be applied to the response body. The numeric order number is
represented by (\d+), which in regular expression parlance is a numeric sequence of one or more consecutive digits.
Because it’s in parentheses, it represents a regex capturing group, meaning the regular expression can be
interrogated afterwards for the matched value. We use the matched value in the output expression. $1 means the first
capturing group, or the part matched by (\d+) in other words.
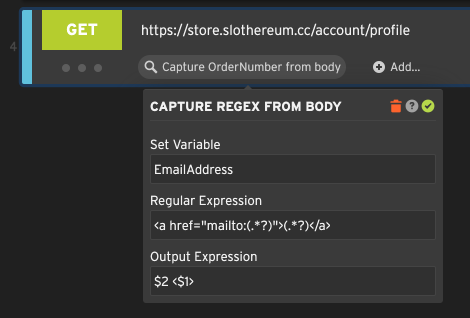
Example: Capturing user info from a profile page
Let’s say you want to use a regular expression to capture an email address from an HTML page. It occurs in the HTML in a format like this:
<a href="mailto:jeff@boomhauer.org">Jeff Boomhauer</a>
We can create a regular expression to capture the dynamic parts:
<a href="mailto:(.*?)">(.*?)</a>
Notice that this expression actually has two capturing groups. The first capturing group matches the email address,
and the second capturing group matches the name. We can refer to these in the output expression as $1 and $2,
respectively. If we only cared about the email address itself, we would use $1.
If you wanted your captured variable to have a different format, you could use this same regular expression but change the output expression.
| Expression | Output |
|---|---|
$0 |
<a href="jeff@boomhauer.org">Jeff Boomhauer</a> |
$1 |
jeff@boomhauer.org |
$2 |
Jeff Boomhauer |
$2 <$1> |
Jeff Boomhauer <jeff@boomhauer.org> |
The value represented by the output expression is stored in the captured variable, in this case ${EmailAddress},
so you can use it later in the script.
More about regular expressions
Here are a few common patterns you can use in your regular expressions:
. any character
\d a single digit, 0-9
\w a single "word" character, a-z, A-Z, 0-9
\s a whitespace character, such as a space or a tabYou can use wildcards to represent multiple consecutive instances of the same thing:
\d* zero or more consecutive digits
\w+ one or more consecutive characters
\w+? one or more consecutive characters, non-greedyRegular expressions are powerful, and we don’t have space for an exhaustive reference here. There is an article at Mozilla that provides more background, and you can even find books on the subject.
Form Input Capturers
Loadster can parse HTML that comes back from the server, and extract the value of a form input. This works best for hidden form inputs and other inputs that have a default value set by the server; it won’t be helpful for client-side fields that the users fill out themselves prior to submitting the form.
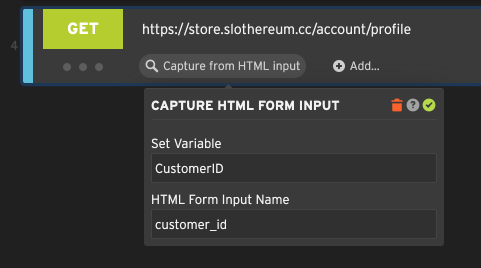
The above example looks for an HTML input element with a name like <input name="customer_id"/> and grabs its
value. It doesn’t have to be a hidden element, but it can be.
In some cases, Loadster might automatically create a form input capturer after recording a script, if it recognizes special form parameters like CSRF tokens and certain framework tokens.
JavaScript Capturers
Capturing with JavaScript is even more powerful than the Text Capturer and Regular Expression Capturer. This type of capturing rule allows you to create a custom JavaScript function. Your custom function will then be executed on the HTTP response to capture a value.
To add a JavaScript Capturer to a step, select Capture with JavaScript from the step’s Add… menu.
To capture a value with JavaScript, you’ll need to implement a custom function called capture(). The function takes a
single argument: the response object, which encapsulates the HTTP response coming back from the server. The output of
your capture function will be assigned to whatever destination variable you specify.
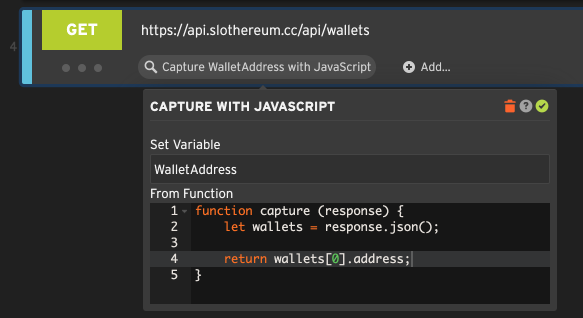
In the example below, we’re using a simple function that parses the response as JSON and extracts a property,
storing it in a variable called WalletAddress that we can use later in the script as ${WalletAddress}.
Example: The simplest capturing function
In its simplest form, you could implement a “capture” function that ignores the response and returns a constant value every time.
function capture(response) {
return "abc";
}Or, instead of a hardcoded value, you could also generate a value on the fly using JavaScript’s Math.random(),
a date or timestamp, or whatever you want. The only requirement is that your function must return a string or something
that can be coerced to a string.
Example: Capturing HTTP response headers with JavaScript
JavaScript can also be used to scan the HTTP response headers and extract a value.
A common pattern in web applications is the “create and redirect” flow. You’ve probably seen it before.
After you submit a web form, the application creates something in the database and then redirects you to a specific
location to view the newly created thing. That way, the request to create the resource is separate from the request to
view the resource, and if you refresh the page afterwards, you’ll simply view the resource again without resubmitting
the form. This happens because the web application responds to the initial POST with an HTTP 302 redirect,
and provides a Location header with a URL to the newly created resource.
To test such a flow in Loadster, we’ll need to capture the dynamic redirect URL from the Location header and then
proceed there with a GET step.
You can use JavaScript to capture the Location header from a response like this:
function capture(response) {
return response.getHeader("Location");
}If you only need part of the Location header, you could parse it out with JavaScript’s regular expressions or
substring functions and only return the part you need.
Of course, JavaScript isn’t required for such a trivial example as this, because you could have done it with a Text Capturer or a Regular Expression Capturer instead.
Example: Accessing the HTTP response body with JavaScript
The response object also makes the entire response body available to your JavaScript functions. To capture the entire response body into a variable, it’s as simple as this:
function capture(response) {
return response.string(); // get the whole body as a string
}More likely, you will want to perform some kind of string manipulation to extract only what you need from the body:
function capture(response) {
var regex = /<title>(.*?)<\/title>/gim;
var match = regex.exec(response.string());
// Return the first matching group from the regex
return match[1];
}While you can get pretty far with the Text Capturer or Regular Expression Capturer, there are times when the response may contain multiple matches, and you need custom logic to select the right one. There may also be occasions when the markup is too complex to parse with a single expression, and you need to write your own parser with JavaScript.
Example: Parsing a JSON response with JavaScript
Many web apps return JSON responses. This is particularly true of RESTful web services and single page applications that exchange JSON payloads with their backend.
While it might be difficult to parse a JSON response with ordinary text or regular expression capturers, it’s quite easy with JavaScript:
// {"users": [
// {"id": 1, "fullName": "Hank Hill"},
// {"id": 2, "fullName": "Peggy Hill"},
// {"id": 3, "fullName": "Bobby Hill"}
// ]}
function capture(response) {
var json = JSON.parse(response.string());
return json.users[2].fullName;
}The example above parses a JSON response and then traverses it to capture a specific value (in this case, the full name of the 3rd user in the list, “Bobby Hill”). You can also use loops and other JavaScript control flow if your JSON structure is more complicated.
Example: Parsing an XML response with JavaScript
XML is also a popular format for web applications and web services. SOAP and XML-RPC applications in particular use a lot of XML, along with some RESTful APIs.
Parsing and traversing XML in Loadster is quite easy:
// <users>
// <user id="1"><fullName>Hank Hill</fullName></user>
// <user id="2"><fullName>Peggy Hill</fullName></user>
// <user id="3"><fullName>Bobby Hill</fullName></user>
// </users>
function capture(response) {
var users = XML.parse(response.string());
return users.childrenNamed("user")[2].childNamed('fullName').val; // returns "Bobby Hill"
}The example above parses an XML response and then traverses it to capture the full name of the 3rd user in the list,
again named “Bobby Hill”. To parse an attribute rather than an element, the attr notation is used:
// <users>
// <user id="1"><fullName>Hank Hill</fullName></user>
// <user id="2"><fullName>Peggy Hill</fullName></user>
// <user id="3"><fullName>Bobby Hill</fullName></user>
// </users>
function capture(response) {
var users = XML.parse(response.string());
return users.childrenNamed("user")[2].attr["id"];
}You could also iterate each user using the length property to find out how many there are:
// <users>
// <user id="1"><fullName>Hank Hill</fullName></user>
// <user id="2"><fullName>Peggy Hill</fullName></user>
// <user id="3"><fullName>Bobby Hill</fullName></user>
// </users>
function capture(response) {
var xml = XML.parse(response.string());
var users = xml.childrenNamed("user");
for (var i = 0; i < users.length; i++) {
var user = users[i];
if (user.childNamed('fullName').val == "Bobby Hill") {
return user.attr['id']; // That's him!
}
}
return ""; // Bobby Hill not found!
}Loadster’s XML parser is based on xmldoc, a pure JavaScript XML parser. More documentation on how to use this parser is available on GitHub.
Example: Capturing a Multi-line Value with JavaScript
Loadster’s ordinary text capturers only evaluate a single line at a time for efficiency reasons. If you need to capture a value that spans multiple lines, here’s a way you could do it with JavaScript:
function capture(response) {
var str = response.string();
var lb = "<textarea name=\"description\">";
var rb = "</textarea>";
var startIndex = str.indexOf(lb) + lb.length;
var endIndex = str.indexOf(rb, startIndex);
return str.substring(startIndex, endIndex);
}Using Captured Variables in Your Script
Capturing a variable would be kind of pointless unless you use it later in your script.
Variables can be referenced in HTTP steps with the usual ${var} syntax. Learn more about Loadster variables in
Variables & Expressions.