Protocol Bot Scripts
Protocol scripts are a sequence of HTTP/HTTPS requests. They are executed by protocol bots.
In a protocol script, you have precise control of each HTTP request’s method, URL, and body. You can also supply dynamic request variables, such as unique usernames and passwords, so that every bot submits different request data.
Since protocol scripts work at the HTTP layer, they are good for testing APIs and simple static websites. They can also work for dynamic web applications.
Technically it’s possible to test almost any site at the protocol level, but you’ll find browser scripts to be easier for testing complex web apps, and protocol scripts for APIs and simple static websites.
Steps in a Protocol Script
A protocol script is a series of sequential steps. These are usually straightforward HTTP requests, but you can use code blocks for more complex situations.
HTTP Steps
An HTTP step makes a single HTTP request, like a GET or a POST. You specify the method, URL, and headers to be sent. If it’s a method that supports a body (like a POST or PUT) you can supply a body too.
You can think of each HTTP step like a visual representation of a curl command.
HTTP steps can also have nested resources, validators, capturers, and other attributes. We’ll cover these in more detail later.
Wait Steps
A wait step makes the bot pause, much like a real user might do when viewing a page and before navigating to the next page.
In general, adding realistic wait times to your script is a good idea if you want realistic test results.
Code Blocks
In a code block, you can write your own JavaScript to make requests and parse responses, together with loops, if statements, etc.
Keep in mind that the JavaScript in your code blocks doesn’t run inside a web browser, it runs in a sandboxed environment on Loadster’s engines.
In code blocks, you have access to modern ECMAScript syntax like the () => {} arrow functions and const and let,
as well as common parsing functionality like JSON.parse(str) and XML.parse(str). You also have
Loadster’s own http object that is basically a user agent for making HTTP requests.
Code blocks are powerful for implementing control flow, looping, or conditional logic in your scripts. You won’t need them for every script, though. If you just want to execute steps in a linear fashion you won’t need code blocks at all.
You can learn more about code blocks and see some examples in the Code Blocks section.
Include Script
You can include another script in your script. This is useful if you have a common set of steps that you want to reuse in multiple scripts.
Comments
It’s often a good idea to add a few comments to your script. These are just there for the benefit of you and other humans – bots ignore them.
Recording a Protocol Script
Recording a protocol script from your web browser with the browser extension is often the easiest way to get started.
Recording is especially helpful for static sites with lots of page resources (images, CSS, JS, etc) or dynamic web applications. It can also be useful for testing APIs that serve as the backend for a single page web application (SPA) because the requests to these also originate in your browser.
Installing the Loadster Recorder browser extension
To record your browser traffic into a Loadster script, you’ll need the free Loadster Recorder for Chrome or Loadster Recorder for Firefox browser extension.
After you’ve installed the extension in your browser, expand it by clicking the extension icon in your browser’s toolbar. You can toggle the switch to enable or disable recording.
The browser extension is open source and you can review the source code on GitHub.
Recording your browser activity
To start recording, open a new or existing script and hit Record. Loadster will start communicating with the Loadster Recorder browser extension.
Enter the URL of the first page you want to record.
When you start recording, Loadster will open a new browser tab to that location. Whatever you do in that browser tab will be recorded as an event and show up in the recording log. Traffic in your other browser tabs is not recorded.
Click Stop Recording when you’re finished.
Filtering which browser events should be included in your script
Many sites have third party trackers, ads, and other content that aren’t in scope for your testing. You might want to filter these out from the recording so they aren’t included in your script.
Filtering them out results in a cleaner script, and also avoids redundant traffic to third party domains out of your control. However, if you have concerns about the performance of these third parties you rely on to serve your customers, leave them in or coordinate with them for a comprehensive test.
After you finish recording, Loadster presents you with a list of recorded domains and event types. Uncheck any domains and/or event types that you don’t want included in your script.
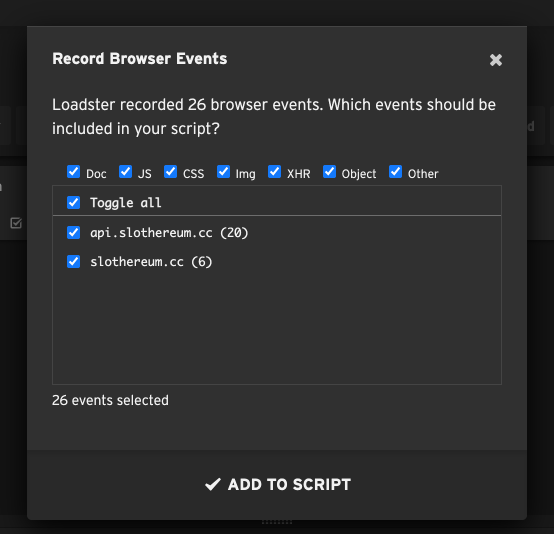
When you click Add to Script, Loadster converts your raw traffic into steps and append them to your script.
You might notice that many of the events you recorded have been folded up as resources of other events. When you record a protocol script, Loadster does its best to determine which requests are primary requests (pages) and secondary requests (page assets like CSS, JS, images, etc). For this reason, the number of steps added to your script might not match the number of raw events that were recorded.
Best practices for recording protocol scripts
Recording saves time, but it isn’t always perfect! Avoid the temptation to hastily record and play back scripts without reviewing and understanding them first.
When you record your browser traffic into a protocol script, Loadster tries to guess the relationship between pages and their resources. Typically, images and stylesheets are recorded as static page resources under the pages that requested them, rather than independent steps. However, there are cases when you may need to clean up your script after recording to get it just right.
You can simply delete any recorded steps that you don’t want in your script.
Also, if you’re testing a dynamic site with complicated interactions (such as an OAuth flow, a series of form submissions, or a single page application), the recorded script might need to be edited to allow for repeated use. You might even need to introduce variables in your script so it submits different data each time it’s played.
Always play through your script in the editor after recording or making changes, to make sure it runs as intended and does what it’s supposed to.
Common problems when recording protocol scripts
Recording all your browser’s HTTP requests and turning them into a useful script isn’t always trivial. There are a few common problems that might affect your recording.
Too much junk traffic is recorded, cluttering up the script
Many websites include a lot of analytics, trackers, 3rd party scripts, etc. You don’t always want these included in your load test. They might be served from domains you have no control over, are hopefully scalable, and whose owners might not appreciate an unexpected load test.
To avoid too much of this junk traffic, use the domain and content type filters described above. Typically only the domain(s) and content type(s) in scope for load testing should be part of your protocol script.
Calls from the Beacon API aren’t recorded reliably
By design, requests from the browser’s Beacon API
via navigator.sendBeacon() are sent in the background at the browser’s leisure.
These are POST requests, and the Loadster Recorder extension is able to capture them when it sees them, but there’s no guarantee they’ll happen when you want them to when recording a script. In particular, beacons that fire at the end of the browsing session (when a tab is closed) may not be captured at all because the Loadster Recorder might have already stopped listening for events before the browser sends the requests.
If you want beacon requests included in your script, you may need to add or rearrange them manually after recording the script.
Playing Protocol Scripts
Playing a script in the editor is your chance to discover and fix errors in your script before putting it to use. When you play a script in the editor, it runs with just a single bot and reports extra diagnostics, giving you the best opportunity to find and fix script errors.
There are two ways to play a script in the editor: Play and Fast Play.
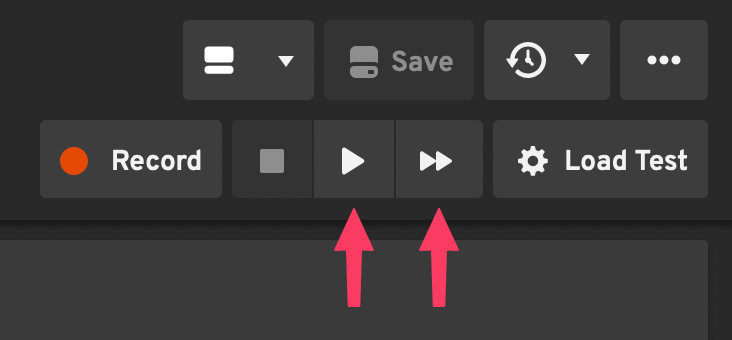
Fast Play skips all wait steps in your script, to save you time debugging the script. Play executes the wait steps, so it takes longer but is more realistic.
As your script plays, you’ll see flashing lights to show which step is active, and a status displayed when the step finishes.


Successful steps will appear with three green dots showing underneath the type of HTTP command (GET, POST, etc.). If an error was encountered, these same three dots will appear in red.
You can stop a script playing by clicking Stop, or wait until it finishes.
Viewing script logs and results
After you play a protocol script in the editor, the Logs and Requests tabs appear. These have extra information about the script that you just played.
In the Logs tab you’ll see output from each step, such as the URL, the size of the response (in bytes), info about additional page resources, and any errors that may have occurred.
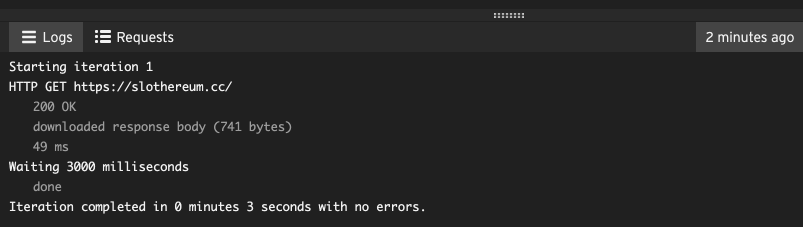
In the Requests tab you have a tree view of every HTTP step that was played, so you can drill down to see the full requests and responses from each step, including the full request and response body.
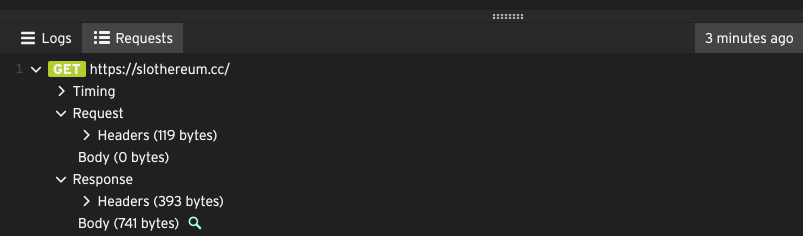
It’s common to receive some errors the first time you play your script. If this happens to you, don’t worry! You can figure out what happened and edit your script to fix the error, then play it again.
Troubleshooting with the script logs
If your script has errors, you’ll see them in the log. These errors can be helpful in determining what went wrong. Errors show up in red.
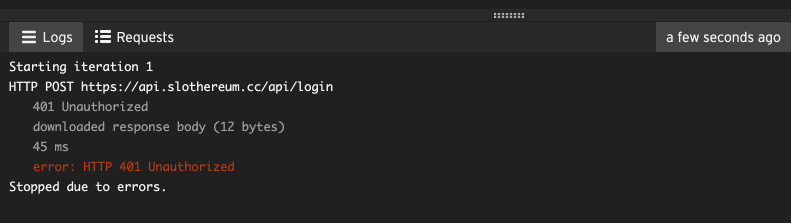
The error displayed above is an HTTP 401, which means the server said this caller is unauthorized to make the request. An HTTP 401 usually means authentication is required, or the authentication credentials submitted with the request were invalid.
When you’re working with protocol scripts, it’s helpful to know the HTTP Status Codes and how your site uses them. Here are a few of the common ones:
200- Successful201- Created301- Moved Permanently (a type of redirect)302- Moved Temporarily (another type of redirect)401- Unauthorized403- Forbidden404- Not Found (the URL might be incorrect or the resource is missing)500- Internal Server Error502- Bad Gateway503- Service Unavailable
Your script might also encounter other errors that aren’t HTTP status codes, such as validation errors or some other type of error.
Troubleshooting with the script requests and responses
If you can’t figure out what went wrong from the logs, Loadster also provides a more detailed view of the script results. The Requests tab shows a tree-like view of every HTTP step that was executed in your script.
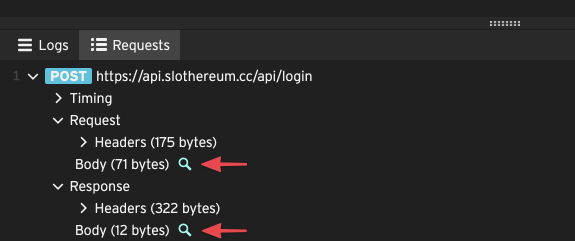
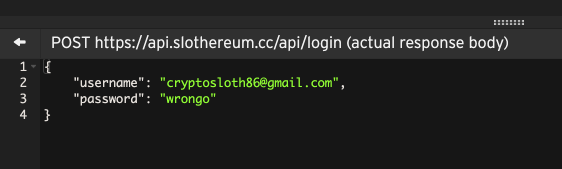
You can expand each section in the tree for details about the request and response. You can even view the full request or response body by clicking on the magnifier.
Troubleshooting with your application logs
If you still can’t figure out the cause of the errors, look to your application and server logs. Testing web applications is always specific to the application, so when all else fails your application itself is the best place to look.
Knowing your own application and checking the logs is especially important if your site hides the details of errors with generic or unhelpful error messages.
Editing Protocol Scripts
You can add, edit, and remove individual steps in your script. You can also drag steps to rearrange them.
Here are a few things that work for all kinds of steps:
- Add a step by clicking the toolbar button with the relevant step type.
- Select a step or steps by clicking (or shift-clicking) in a neutral area of a step, such as the left handle.
- Copy and paste steps by selecting them and using your ordinary keyboard shortcuts (Ctrl-C, Ctrl-V, Cmd-C, Cmd-V). You can even copy and paste them between scripts.
- Duplicate a step by hovering and clicking on the duplicate icon on the right-hand side of the step.
- Delete a step by hovering and clicking on the delete icon on the right-hand side of the step.
- Disable or enable a step by hovering and clicking the toggle icon on the right-hand side of the step. Disabled steps remain in your script but are not played (like commenting them out).
- Drag to reorder steps by clicking in a neutral area, such as the left handle, and dragging to a new position.
Aside from that, each type of step has its own attributes that you can edit individually.
Editing Wait Steps
Wait steps are simple. They simply make the bot pause execution of the script for a certain number of seconds.

To change the duration of the wait, click the number of seconds, and enter a new number.
Having realistic wait times is important. Normally you should try to make your scripts run at the same cadence a real user would. If your wait times are unrealistic, your test results might be too.
Editing HTTP Steps
In its simplest form, an HTTP step represents a single request to the server, much like a real user’s browser or a programmatic HTTP client would make.
Every HTTP step specifies a method and a URL.
HTTP Method
The HTTP method is a standard part of every HTTP request. The most commonly used methods are GET and POST, but many applications (especially RESTful APIs) make use of others such as PUT and DELETE also.
To change the method of a step, click on it and select the new method.
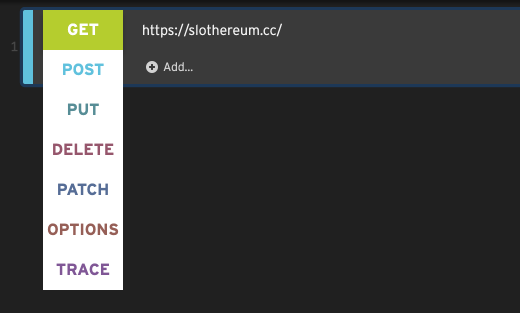
If you recorded your script, you’ll rarely need to change the method of a step. However, if you’re creating steps manually, it is important that they have the correct method.
Request URL
If you made it this far in life, you know what a URL is. You can edit a step’s URL by clicking on it.

If you’re editing query string parameters in a URL, make sure they are URL encoded! For example, a space in the query parameter
values should be encoded as %20. Loadster has some formatting functions
like urlencode(str) to help with this.
Request Body
The request body is an optional part of certain types of HTTP requests. Usually, POST and PUT requests have
request bodies and other methods like GET and DELETE do not. When a request body is present, HTTP requests should
have a Content-Type header to tell what type of content is being sent.
Loadster supports any content type you want to use. Content types that are usually text-based (JSON, XML, form fields, text, etc) are directly editable in the script editor, while binary data is not directly editable but can be uploaded from a file.
Make sure the request content type matches what your server is expecting.
The most common type for submitting a web form is application/x-www-form-urlencoded. However,
some forms (such as file upload forms) send multipart/form-data. REST APIs might expect
application/json, application/xml or even text/xml.
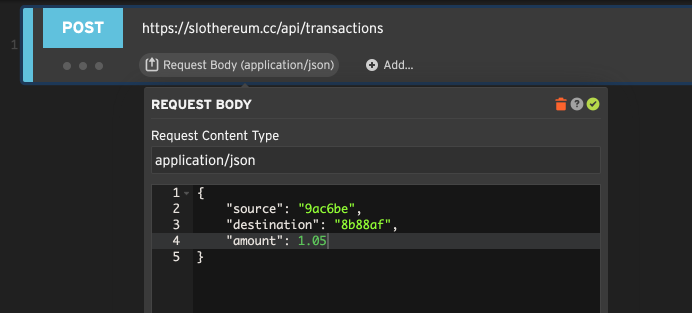
Editing a JSON, XML, or plain text request body
Many APIs expect a JSON body with POST or PUT requests. Setting the step’s Content-Type header to application/json
or another text-based content type will open the text editor.
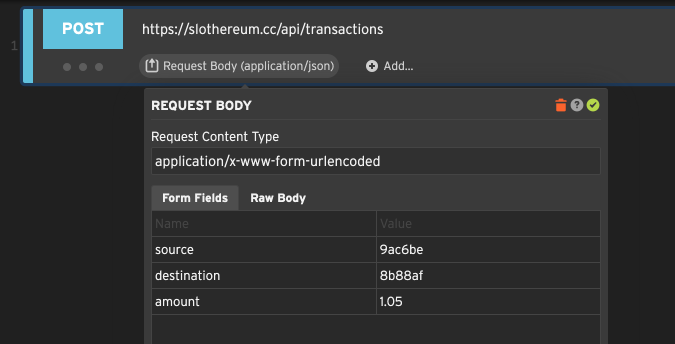
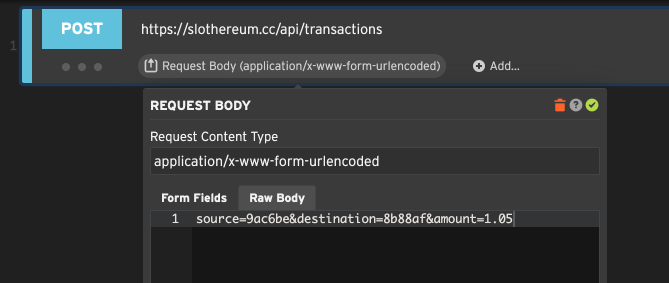
Editing a URL encoded form body
Web forms are often submitted with Content-Type: x-www-form-urlencoded, which means the fields on the form get
strung together like URL params and sent in the body. If you set the request body to x-www-form-urlencoded
Loadster gives you the choice of editing individual fields or editing the raw encoded string.
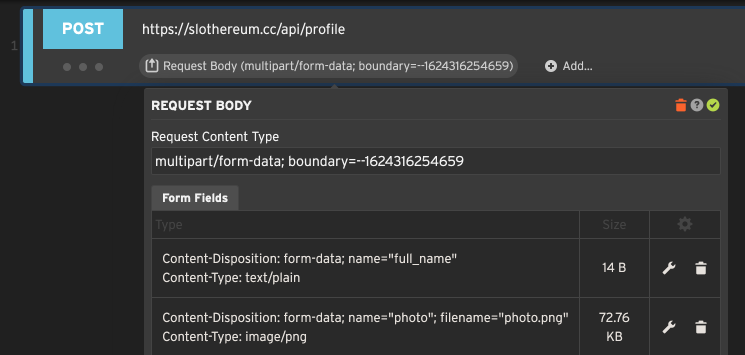
Editing a multipart form body
The Content-Type: multipart/form-data header is usually reserved for file uploads. Setting this content type
allows you to edit each part separately, and even attach files to be sent as parts for file uploads.
Interpolating variables in the request body
Watch out for the Interpolate variables in request body option. This checkbox tells whether any
string in the body that matches Loadster’s expression syntax should be
interpolated into a value. Unless you are submitting variables with the step, it’s safest to uncheck this,
so that strings that just happen to resemble ${variables} are left literal.
Request Headers
Request headers are sent with every HTTP request, as required by the HTTP protocol. Most of the time, Loadster automatically sends default headers for you, and you don’t have to worry about them much.
But sometimes you might need to specify headers yourself. You can add a header with Add request header from the step’s Add… menu.
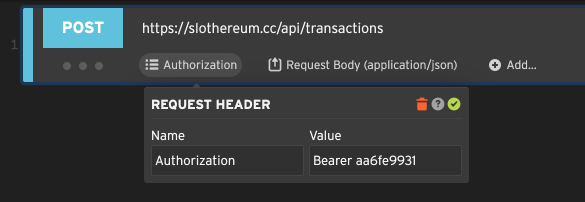
The example above sets an Authorization header with a bearer token to identify the caller. If you need to, you can
add multiple headers to the same step.
Authentication
Loadster’s protocol scripts have built-in support for Basic, Bearer, and NTLM authentication. If you want to use something else, chances are you can make it work with custom headers.
You can enable authentication for a step with Add authentication from the step’s Add… menu.
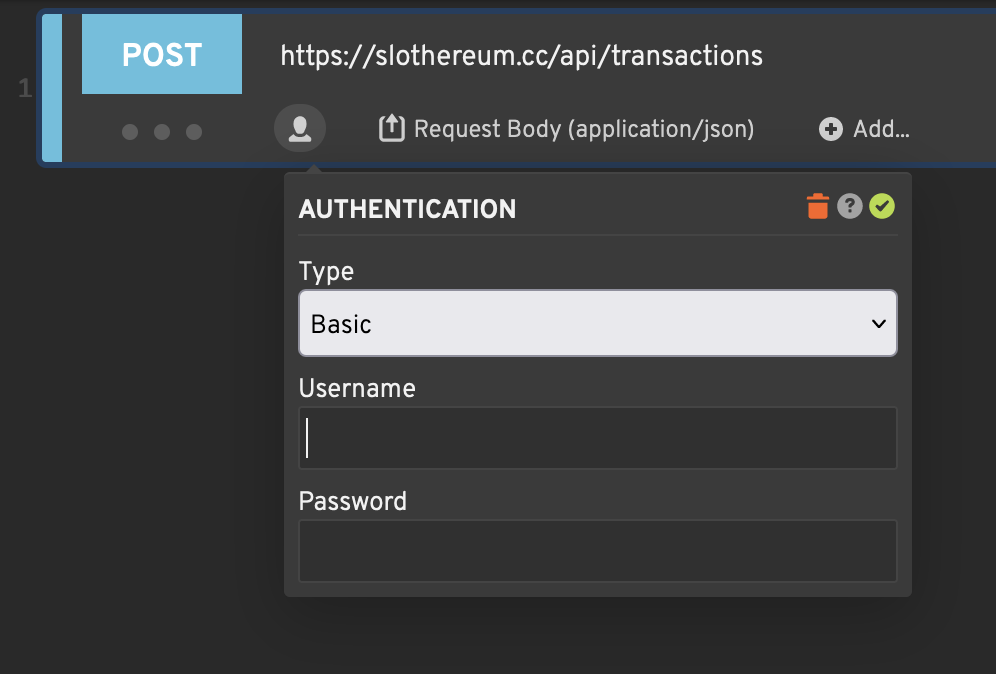
Basic Authentication
HTTP Basic Authentication has been around for decades, and provides a simple way to encode a username and password
in an Authorization header. This approach has mostly fallen out of favor with web applications, but remains
popular with APIs where a simple stateless authentication mechanism is desirable.
Bearer Authentication
HTTP Bearer Authentication is commonly used with OAuth, and other situations where authenticating with a single API
key is desired. The Bearer token is passed in an Authorization header by itself without any kind of encoding.
NTLM Authentication
Some Microsoft servers, particularly for in-house applications, use the NTLM protocol to authenticate users. This is a challenge-response protocol that involves some kind of identity manager such as Active Directory. It requires a Windows “domain” and a username and password.
Page Resources
An HTTP step can optionally include additional page resources that piggyback on the primary request.
These are usually static assets like CSS, JavaScript, and images.
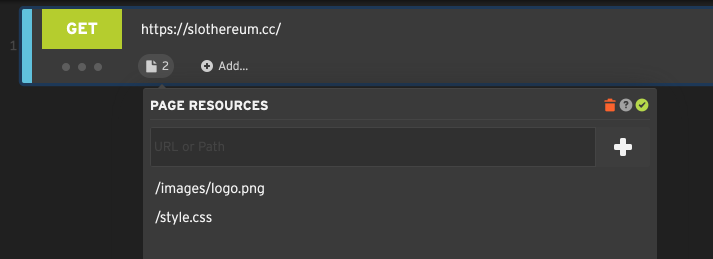
If your step includes additional resources, the bot will request them in parallel after the main request completes, much like a web browser would load an HTML page and then load the associated images, CSS, JS, etc.
Loadster’s reported response time for this step will include the time it takes to load these resources.
Including page resources in a step only makes sense if the request is for a web page and you want the full page with static assets grouped together in a single response time. There’s no need to use them for APIs.
Validation Rules
Validation rules (or validators) are a way to assert that the server responds to a step the way you want it to. By adding validation to a step, you can make the script throw an error if the response isn’t what you expected it to be.
You can add one or more of these to any HTTP step from the step’s Add… menu.
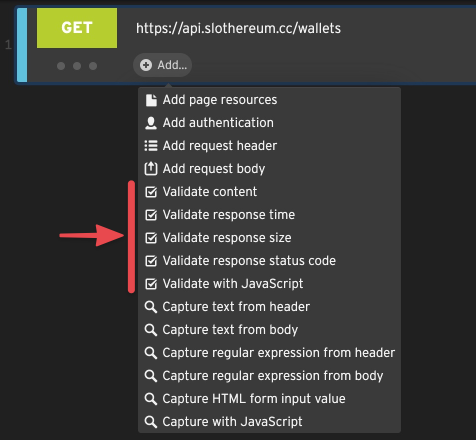
You can learn more about them in the Validation Rules section.
Capturing Rules
Capturing rules are a way to capture, or extract, a value from an HTTP response. The capturer stores it in a variable that you can reuse later in the script.
To add a capturing rule to an HTTP step, select any of the capturers from the Add… menu on that step.
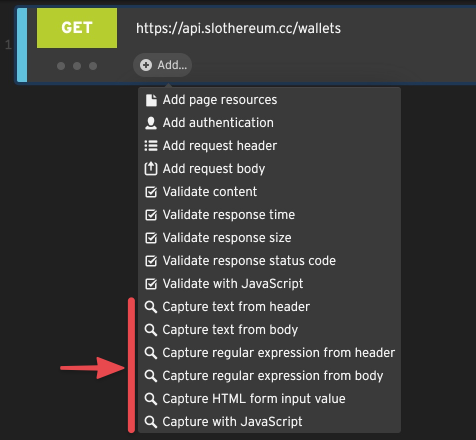
Capturing and reusing values from server responses is often necessary when testing dynamic web apps or APIs.
Learn about the types of capturing rules and see some examples of when to use them in Capturing Rules.
Protocol Scripting Best Practices
It’s important that your script should represent a single user’s behavior as realistically as possible. If you test unrealistic behavior, you’ll get invalid results. Your test results are only as accurate as the behavior the test simulates.
- Include all relevant HTTP requests, so the bot hits your server like a real user would.
- Make sure to use variables for any request data that should be unique for each user.
- Play your script after every change to make sure it runs properly.
If you’re testing a dynamic site and having a hard time creating a protocol script because the flows are too complicated, it might be time to try browser scripts.