API Performance Testing
Why Performance Test Your API?
Developers want to build on an API that’s fast and reliable. Customers want to know that the API can be relied upon, and won’t bog down or crash when they need it most during a traffic spike.
Understanding how your API performs in different traffic situations will save you the stress and high cost of reacting to issues that would otherwise arise in production.
Performance testing makes sense for most types of APIs, including REST, GraphQL, many RPC-style web services like XML-RPC, JSON-RPC, SOAP… and an alphabet soup of other specifications.
Nearly all modern APIs share characteristics that make performance testing them relatively straightforward:
- Stateless protocols. Usually HTTP/S. When we say the protocols are stateless, we mean that each request to the API is self-contained and made independently.
- Request-Response. Most web APIs operate on a request-response model, meaning that the caller or consumer sends a request, and the API answers it.
- Built for programmatic access. API stands for Application Program Interface, so by definition they are meant to be consumed programmatically. Of course that means they’re an ideal fit for testing programmatically too.
Overall, APIs are ideal candidates for automated testing. Their performance is relatively easy to measure and quantify.
API Performance is Multidimensional
There are two things about API performance that might seem obvious, but are worth pointing out.
Every API endpoint performs differently. Unless your API only has a single endpoint, callers will get different response times from one endpoint to the next. To understand your API’s performance, you’ll need to compare response times between different endpoints, and even the same endpoints invoked with different payloads.
APIs perform worse under load than at baseline. Every API is powered by a finite amount of server and infrastructure resources. When many requests are coming in at once, there is resource competition, which means at some point the demand on the API will exceed its ability to process the requests. When this happens, the API’s performance is degraded and everything bogs down, leading to a crash or at the least a bad experience for callers.
Measuring Your API’s Performance Characteristics
Since API performance is multidimensional, we recommend looking at your API through a few different lenses to see the big picture.
Passive API Monitoring
Passive monitoring isn’t really testing per se, but it’s closely related to API performance, so we’ll mention it here.
It means passively actual API traffic and measuring the response times and other aspects of each request. Passive
monitoring is backwards-looking: your monitoring data can show a clear picture of past and present usage, but
it doesn’t help you anticipate how your API might handle increased or different usage in the future.
Passive monitoring can be low-touch (tail -f your server logs) or high-touch (custom instrumentation,
observability stacks, or using APM tools like New Relic or Dynatrace).
Active API Monitoring
Active monitoring means testing your API by making actual requests on a schedule. Active monitoring is also called
“synthetic monitoring” because you generate traffic just to test the API. Like passive monitoring, active monitoring
is backwards-looking: your monitors will tell you how your API responded to synthetic requests at various times and
alert you of errors or anomalies, but they won’t help to anticipate how the API will behave in the future under
heavier load. Active monitoring can be as simple as a cronjob making curl requests and logging the output, or you
can use Loadster’s Site & API Monitoring capability to run monitoring scripts on a schedule and
alert you of any problems.
API Load Testing
Load testing also means generating synthetic requests to test your API, but instead of sending a single request at a time, a load test hits your API with many requests at once. Your API’s performance under heavy load might be far worse than it was under minimal or baseline traffic! An API that runs fine normally might crash when there’s a traffic spike. Crashes during traffic spikes are especially bad because they happen at the worst possible time, when the most callers are expecting a response!
How Load Testing Helps You Prepare for Traffic Spikes
Load testing means testing a system with many concurrent requests, to see how the load from all these requests impacts the system. Load testing is most concerned with how API performance changes or degrades as the load increases.
The intensity of load and the duration of load can both impact your API’s performance. You may find that your API handles moderate traffic spikes just fine, but a larger traffic spike exhausts backend resources and crashes the system. Your API might recover gracefully from a short traffic spike, only to collapse if the heavy traffic is sustained.
Different types of load tests are meant to test your API with various traffic spike intensity and durations.
Baseline Load Testing
You might want to start with a load test simulating some reasonable baseline amount of traffic. A baseline load test should generate only a modest amount of load and doesn’t need to run very long.

Let’s say in real life your production API receives about 20 requests per second: a baseline load test would simulate this typical amount of load as realistically as possible, so you have a baseline “blue sky” test result to compare with more aggressive tests later.
Spike Testing
A spike test simulates a traffic spike, or a short burst of heavy traffic, that is significantly higher than the amount of traffic your API normally experiences. The spike portion of a spike test is short but intense.

Traffic spikes could be intermittent (a minute or so) or longer (several hours). When you run a spike test, you’re trying to find out how much worse the API performs during the traffic spike than at baseline.
Ideally you’ll have some performance requirements in mind so you can tell if your API passed or failed the spike test. For example, you could say that during a traffic spike the API must maintain average response times less than 500ms, and that the 95th percentile response time not exceed 2.0 seconds.
Stress Testing
A stress test also means hitting the API with excessive traffic, with the goal of actually breaking it. Stress tests have maximum load intensity over a fairly short duration.

The primary goal with a stress test is to determine what happens when the API is pushed past its limit. Does it just get progressively slower for all callers? Does it rate limit them with an HTTP 420/429 and tell them to try again later? Does it gracefully prioritize certain critical operations over other less critical ones? Or does it block all incoming requests to the point of 100% failure? Worst of all, does it lose data or commit half-finished transactions that leave the system or your customers’ data in a permanently broken state?
Stress testing is a way to mitigate these disasters before they happen. You should seriously consider it, particularly for read-write APIs.
Soak or Stability Testing
A soak test, or stability test, focuses less on the intensity of excess load on your API, and more on the duration of the load. Soak tests typically generate moderate traffic over a long duration.

Some APIs have gradual resource leaks that get worse over time. For example, your backend might leak memory by holding onto global references to objects after the requests have already been handled, or failed transactions might leave database connections open until they eventually run out. Sneaky problems like this might go unnoticed for a long time and be hard to reproduce, but a soak/stability test can detect them. The likelihood of such problems depends on your API’s architecture and technology stack, but soak testing is never a bad idea.
Performance Tuning & Optimization
A repeatable load test can be very helpful when you’re tuning your API’s configuration and environment for better scalability. You’ll want to test and re-test the API with the same load after each experimental change. A repeatable performance test will tell you whether the change caused performance to get better, stay the same, or get worse. It’s usually best to change just one thing at a time, running the same load test before and after for comparison.
Planning Your API Load Testing
A load test is a simulation of real world traffic patterns, but the outcome of the simulation is only as valid as the assumptions going into it. If your test doesn’t represent reality, neither will the results. Planning realistic tests is important.
Consider questions like…
-
Which API endpoints and functionality are in scope for load testing? Start with the endpoints that are most critical for your business, most likely to have performance problems, and most often invoked. In an ideal world, the distribution of endpoints you load test will mirror the distribution of real-life requests coming in from your API consumers.
-
What test payloads should be sent to the endpoints? Calling the same endpoint with a different payload might produce a very different result! For instance, invoking a search endpoint with a common term will return a bigger response than searching for an uncommon term, and it might be slower (because there’s more data to retrieve) or it might be faster (because the results were cached on the backend). Testing your API’s performance with identical payloads is a common pitfall you’ll want to avoid, so when building your load test, try to use varying payloads.
-
How fast does the API need to perform? Under how much load? You and your team should agree on performance requirements that dictate how fast the API needs to respond, possibly broken down for critical endpoints that might be faster or slower. Additionally, you should have scalability requirements for how many simultaneous requests or concurrent consumers the API needs to handle at peak, while still delivering acceptable performance.
Document and share these considerations with your team when planning your load tests. That way, everyone shares the same assumptions, and you can collectively agree whether your API meets the performance requirements.
The API Load Testing Process
Most of this guide is focused on ideas and methodology, but we’ll share some examples for Loadster. If you have a different tool you can probably apply many of the same ideas.
Creating API Test Scripts
Loadster’s Protocol Bots are ideal for testing APIs because they automate requests at the HTTP layer (as opposed to Browser Bots which use headless browsers to test websites and web applications). Protocol Bots run protocol scripts.
Each step in a protocol script represents an HTTP request. The step includes the HTTP method and URL, and you can optionally add authentication, custom headers, and a POST or PUT request body or payload.
A script can hit a single endpoint, or it can call multiple endpoints one after another. When invoking an API, it’s common for the consumer to parse the output of one response and then use it in the payload of a follow-up request, often chaining together many related requests in sequence. A test script can do this too, so that it mimics your real API consumers as closely as possible.
When the script runs, each step fires off a request to your API, gets back a response, and reports how long it took.
Your script can validate the response and capture or extract values from it to use later on.
There are several ways to build scripts in Loadster. You can add steps manually, import them from your API’s OpenAPI/Swagger specification (if you have one), or record them in your browser with a browser extension (if your API is the backend of a web application).
Read up on Protocol Scripts in the Loadster manual to see how it’s done.
For API load testing, you’ll need at least one working test script that hits one or more of your API endpoints.
Designing API Load Test Scenarios
In a load test, many bots run your scripts in parallel, simulating lots of API consumers hitting your API at once. You can load test with different levels of traffic simply by changing the number of bots.
The bots can originate from the same geographical region, or different regions. Distant geographical regions will probably introduce extra latency. If your API consumers are geographically distributed, spreading the bots across various regions is a good idea.
Loadster’s bots arrive in groups. The number of active bots increases gradually and then holds steady and then decreases, according to a pre-set pattern.
Here’s an example of a load test with two groups of bots, ramping up with an aggressive pattern, maintaining steady load for a while, and then ramping down with a natural bell-curve drop off pattern.
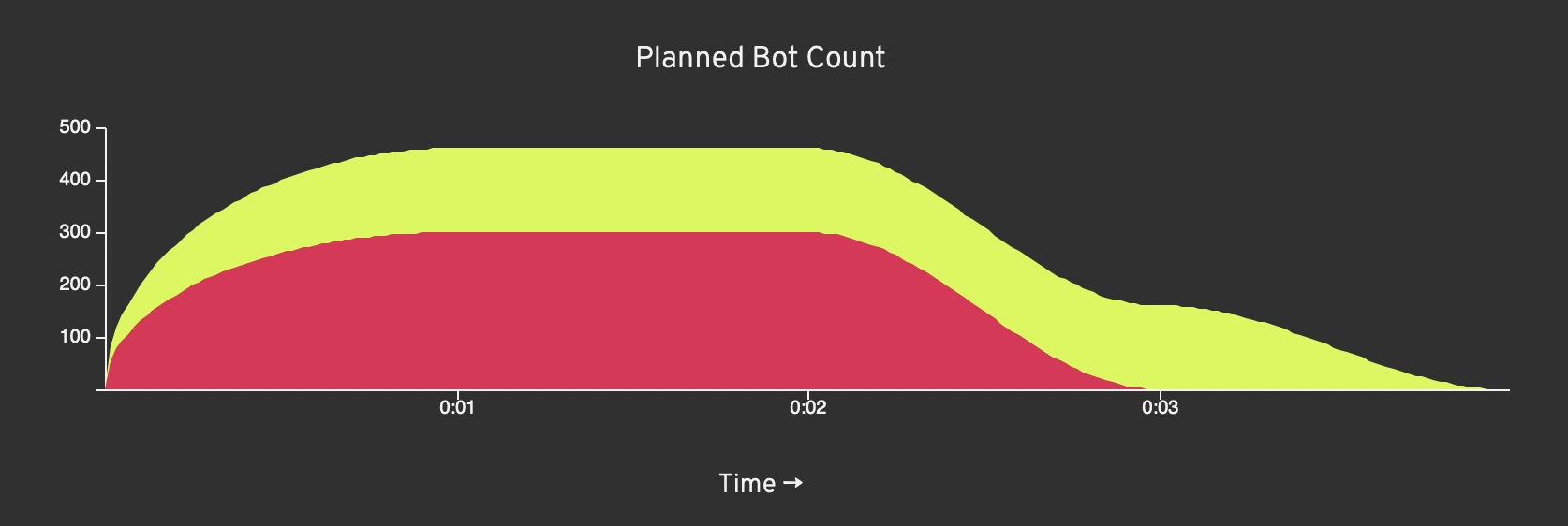
Each bot will run the script over and over, as long as time remains in the load test. That means a load test with 200 bots simulates a sustained load of 200 concurrent users/consumers hitting your API. If your script is short, that could result in many times more iterations of the script over the course of the load test.
Estimating How Many Bots To Run
When you load test an API, you’re probably thinking in terms of throughput: requests per second or transactions per minute or something like that. How many bots are required to reach your target throughput isn’t immediately obvious.
Translating throughput into numbers of bots requires a bit of arithmetic, and maybe trial and error. Let’s say for example that your script (with wait times) takes 15 seconds and generates 8 requests, and your aim is to simulate 200 requests per second. First, we divide 8 requests by 15 seconds, and find that a single bot running script averages about 0.53 requests per second. We want 200 requests per second across the entire load test, so we divide 200 by 0.53… turns out we’ll need about 378 concurrent bots running this script to generate 200 requests per second sustained throughput.
In practice, the request throughput per bot can vary. If your API slows down under heavy load, each request will take longer, so the entire script will take longer, reducing the throughput from each bot. If this happens, congratulations: the load test was worth running and you’ve found a bottleneck!
Running API Load Tests
Once you’ve designed a test scenario in Loadster, you can immediately launch a load test by clicking the Launch button. If you selected cloud regions for your bots, there’s nothing for you to install and no infrastructure to configure: all the engines are launched on demand in Loadster’s AWS and GCP cloud regions. These cloud instances typically spin up in about 90 seconds, give or take a few.
Watch the load test as it runs.
In particular, you’ll want to keep an eye on response times, which are the bots’ measurements of how long it takes to send a request to your API and get back a response. Response times are shown in aggregate (average, 50th percentile, 90th percentile) and also broken down by HTTP method and URL. If your script tests multiple endpoints, make sure to look at the performance of each endpoint individually, because your API’s performance can vary drastically from one endpoint to the next.
Also look at the Transaction Throughput graph to see the rate of requests per second (“hits”) and total iterations of your script (“iterations”). Similarly, the Transactions graph shows the cumulative totals of each of these throughout the load test.
If Loadster detects any errors, these will show up in the Errors section, broken down by error type and also the URL on which the error occurred. Errors can be raised automatically (connection failed, an HTTP 4xx/5xx response, etc) or by your own validation rules if you added those to your script.
After the test finishes, Loadster generates a report automatically so you can share the outcome with your team and stakeholders. Other tools might do the same.
Common Load Test Failures
Determining whether the API passed or failed a load test is up to you. It ultimately depends on your performance and scalability requirements, but there are some common failure states to watch out for.
Load test failures can be broken down between systemic problems (problems that affected the whole API across many endpoints) and specific problems (problems that only affected a single operation, endpoint, or area).
Degraded Performance “Hockey Stick” Patterns
As the bots ramp up and load on the API increases, the response times might change. It’s very common for an API to perform well under minimal load but then fail under heavy load. This is most readily apparent in a load test with a long, steady ramp up pattern. Consider the following relationship between active bots and transaction throughput and response times, with graphs simplified for clarity.

The response times looked good at first! Throughput increased linearly as more bots came online. But then what happens? Throughput hits a wall, response times shoot up as incoming requests get blocked or queued, and errors increase dramatically.
This represents a textbook case of a load test hitting a scalability bottleneck. A limited resource on the servers becomes exhausted, which limits throughput, and additional requests get backed up waiting on the bottleneck.
This systemic problem is analogous to a traffic jam, where all the cars have to slow down once a freeway reaches capacity. In your API the limiting factor might be the database connection pool, the server connections or workers, or even some hardware limitation, instead of the number of lanes.
Script Or Test Data Problems
Your load test might have errors caused by mistakes in your script or bad test data. This type of error usually isn’t related to the load on the system. It will likely show up as a specific problem, with all errors coming from a single operation or a single step in your script.
If you see the same errors happen consistently even under minimal load, double-check your script and the parameterized data that it submits to the API. If each bot is submitting unique data, check that the data is what the API expects.
Errors That Only Arise After Sustained Load
If you’re running a stability test or soak test (as described above), you’re looking for problems with your API’s ability to handle sustained load, over hours or even days.
The typical systemic failure state here is for everything to be fine for quite a while, and then errors suddenly show up everywhere, even though the load was steady all along. That might indicate a memory leak or resource leak of some kind in your API. Take these seriously, since they will inevitably happen in production too, given enough time.
Intermittent Errors (Network Blips, Random Stuff)
When traffic is going across the internet and 3rd party services outside of your control, it’s possible you might see a blip every once in a while.
In a load test that generates thousands or millions of requests, one or two connection reset errors might be nothing to worry about. If the error isn’t reproducible and everything looks good otherwise, you might not need to get too hung up on it.
My API Crashed Under Heavy Load… Now What?
If your API failed a load test, you’re in good company! Pretty much any API will fail if you hit it with enough load. A failed load test is actually a useful outcome, because now you know your API’s breaking point, and can take steps to improve the situation.
If you had a scalability requirement and the API failed to meet it, consider making changes to the API’s codebase or environment so it does better next time.
A single endpoint that’s consistently slow may indicate a specific problem with that endpoint, but when many endpoints are slow it’s more likely a systemic bottleneck with your infrastructure or a layer of code. APM tools can be very helpful in pinpointing exactly what the bottleneck was.
Here are a few possibilities to check…
- Was the database working really hard? Check if certain queries were particularly slow. These might point to a missing index. If the indexes and tables are optimized, maybe the database just needs to be more powerful.
- Were database operations slow but the database itself wasn’t working hard? It’s likely an improperly sized database connection pool that prevents your API from getting a database connection when it needs one.
- Was the CPU on your application server(s) maxed out? Check if it they were hitting memory limits. With modern languages, high CPU usage can often be a side effect of insufficient heap memory, with the garbage collector desperately thrashing to reclaim some memory. If the memory was fine, perhaps there is code that can be optimized. If the code is optimized and there’s plenty of memory, maybe you just need more hardware.
- Was neither the application server(s) nor the database maxed out, but requests were slow anyway? Check if your server’s max connections limit was too low, causing incoming requests to be queued. Also check if an intermediate layer (like a firewall or reverse proxy) might have hit its limit, also causing incoming requests to be queued before they even hit your application servers.
Load testing is an iterative process, and it’s smart to run multiple tests with different configurations to get a comprehensive understanding of your API’s performance and scalability.
Reducing the Risk of Production API Failures
API performance testing is all about reducing the risk of failure. The amount of effort you put into testing your API should be proportionate to the impact that its failure would have on your business, your customers, and your own personal wellbeing.
It’s impossible to completely eliminate the risk of performance-related API failures, but that’s okay! You can greatly improve your odds by running some tests and tuning around the outcomes. Work with your colleagues to determine performance and scalability objectives, and then address them through a series of baseline load tests, spike tests, stress tests, and stability tests. Aim to explore and mitigate all the different ways your API could fail.
If you only have time for one or two rounds of testing, start there. Even that helps. API performance testing is an iterative process that gets easier as you go.
Ready to reduce your API performance risk?
Start load testing your API, with 50 units of free Loadster Fuel to power your first few cloud tests.
Start Testing for Free