Front-End vs. Back-End Performance
Defining the Front-End & Back-End
When a visitor hits your site, before the content magically appears in their browser, it passes through multiple application layers. We sometimes loosely define these layers as the “front-end” and the “back-end”.
The front-end consists of things that run inside the browser: HTML, CSS, JS, images, etc. The back-end is the code and infrastructure that’s responsible for serving up data to the browser, often including servers, firewalls, proxies, databases, and application logic.
There has been widespread advocacy and evangelism around front-end performance optimization. Tools like Google PageSpeed Insights and Web Page Test, and the built-in developer tools in your browser, make it easy to audit your site’s front-end performance to see how it stacks up. The tools even suggest helpful improvements automatically. Tips like reducing the number of requests, shrinking images and other static content, and offloading static assets to a Content Delivery Network (CDN) are common and helpful suggestions.
Front-end optimizations are the “low hanging fruit” because they are relatively straightforward to implement. Some are so straightforward, in fact, that a bunch of companies offer fully automated solutions that optimize your site’s front-end performance without writing a line of code.
Back-end optimizations, by contrast, are often harder to measure and solve with easy formulaic rules… but they are just as important, especially when it comes to guaranteeing your site can maintain good performance even under heavy traffic.
The “80/20 Rule of Web Performance”
Many have sought to apply the Pareto principle, or 80/20 rule, to web performance optimization. The claim is that about 80% of the time to fully load a site is front-end processing, and only 20% is back-end processing, so it follows that optimizing the front-end will return the most noticeable improvement in UX with the least amount of effort.
Measuring Your Site’s Front-End Performance
You can validate if this 80/20 ratio applies to your site fairly easily. Using Chrome Developer Tools or something like it, track how long it takes to load the initial page (HTML only). Then track how much longer it takes to load all the images, CSS, scripts, and ad tracker baloney that go along with it.
The ratio typically looks something like this:

This seems to support the “80/20 Rule of Web Performance”, since most of the time is spent fetching, parsing, and rendering front-end resources (we’ll call it the “front-end time”) relative to the time fetching the initial HTML page from the server (we’ll call this the “back-end time”).
Watch Out, Back-End Performance Isn’t Constant!
If you think that the back-end response times will always be the same as what you measured just now, you’re making a dangerous assumption.
Most likely, you’re taking your front-end/back-end performance measurements when your site is under a small amount of load. At times of low usage, when few users are hitting the site, your back-end is responding as fast as it ever is.
But what happens during a traffic spike? High traffic events can occur at any time and for just about any reason. Ideally, peak traffic means something good is happening to your business, like a successful marketing campaign or because you got featured on Hacker News. But they can also happen because of randomness, stupidity, or even a malicious attack.
Regardless of the cause, heavy traffic can slow down your back-end servers and infrastructure.
Let’s take a look at what can happen to your overall response times, as user load (traffic) increases:
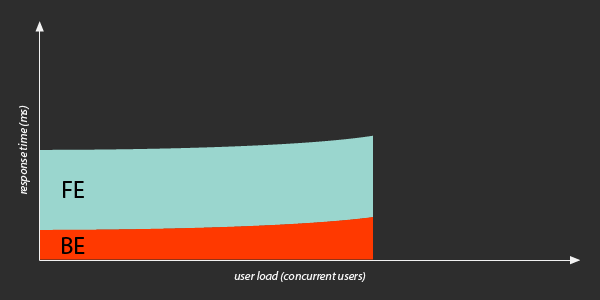
As more concurrent users start visiting your site, the incoming requests compete with each other. The site’s back-end starts to slow down.
Under moderate load, the ratio between front-end time and back-end time is no longer 80/20… more like 60/40.
The back-end time increases, but the front-end time stays constant, since each user has their own browser that parses and renders content independently of the others.
In this way, the ratio of time spent in the front-end and back-end may change, depending on the amount of load on a site.
Back-End Performance Degradation Is Non-Linear
Question: If your backend takes 400ms to return a page when 100 concurrent users are on the site, how long will it take when 200 concurrent users are on the site?
- A. 400ms
- B. 800ms
- C. we have no idea
The correct answer is C. It might be tempting to say the backend will take the same 400ms regardless of load. Or you might assume it will take 800ms (twice as long at twice the load). But the truth is, nobody knows ahead of time how long it will take, because the relationship between concurrency and response time is complicated and non-linear.
What we can say with confidence, though, is that at some point, as load increases, a back-end resource will become saturated and become a performance bottleneck. It could be a database bogging down, or a web or application server hitting its connection limit. It could even be something at the physical hardware layer, like network or CPU or disk.
If more visitors continue to arrive after a bottleneck has been reached, incoming requests begin to queue up even more, waiting for the back-end to process them. Back-end response times then become much worse. The site could become completely unresponsive.
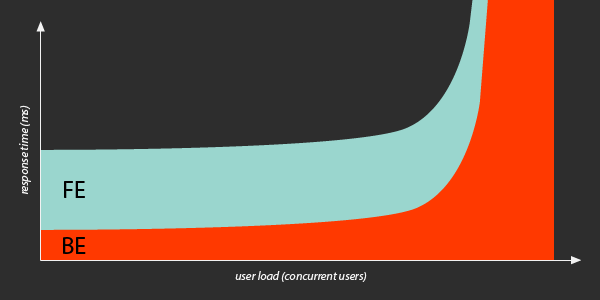
Once a back-end bottleneck has been hit, generalizations like the “80/20 Rule of Web Performance” no longer apply.
That’s why finding a site’s breaking point and scalability bottlenecks is critical, not just to user experience, but to avoiding site crashes and downtime.
Preparing Your Site For Heavy Traffic
The good news is, despite the complexity and risks, it’s possible to prepare your site for a high traffic event.
With the right type of testing you can discover and measure your site’s breaking points and bottlenecks ahead of time, and optimize the back-end servers and infrastructure to handle more load.
Unlike the front-end, which has relatively well-defined prescriptions for optimization, optimizing a back-end requires trial and error. Even for experienced back-end developers, it’s difficult to predict what the bottlenecks might be, or how high the site can scale before reaching its breaking point.
And you probably can’t afford to wait around for your site to crash to discover its bottlenecks. It’s better to proactively test the boundaries ahead of time.
Back-End Performance Testing
Simulating a high traffic event, with lots of users hitting your site at once, is called load testing.
If your load tests are realistic, you’ll be able to determine the site’s breaking point without suffering a production site crash or impacting your real users. You can observe the performance bottlenecks during a load test, and mitigate the problems ahead of time.
It would be impractical to recruit thousands of real people to load test your site. Instead, load testing requires special tools to simulate these users. There are many load testing tools to choose from. Some tools are commercial and others are open source, and all have their own strengths depending on your situation.
Keep in mind that your load test results are only as accurate as the simulation. A load testing tool that simulates the user behavior as realistically as possible will give you more useful results.
Optimizing Back-End Performance
After running some load tests, you’ll have an idea how much concurrent traffic your site can handle before it hits the breaking point. The breaking point is the amount of load at which response times became unacceptable or the errors started to spike.
While load testing, you’ll also want to observe your site’s servers and infrastructure, so you can pinpoint exactly what happens when it starts to break down.
The more visibility you have into your site’s back-end infrastructure, the better. Server logs are nice. Resource monitoring (like CPU, memory, disk, and network) is essential. If your back-end is complex, like a dynamic web application, some kind of Application Performance Management (APM) tool is a good idea too. When load testing, make use of whatever visibility you have, to determine which part of your site’s back-end stack is the bottleneck.
It might be a “soft” bottleneck like a server misconfiguration or insufficient database pool. Or it might be a “hard” bottleneck like maxing out your server CPU or memory or disk. If this is your first round of load testing, a soft bottleneck is more likely.
After you make a change to your site’s back-end, repeat the load test to make sure your change actually helped. Ideally the site should perform better with the same amount of load than it did before the change. If it didn’t, maybe your change was ineffective, or the thing you changed wasn’t really the bottleneck.
Even after you resolve a performance bottleneck, rest assured… there is another bottleneck lurking right behind it! Your site’s back-end will always have a bottleneck of some kind. The goal of back-end performance optimization isn’t to scale to infinity, but rather to validate your site can handle peak traffic, and mitigate the risk of crashing under heavy load.
With each successive round of performance testing and optimization, the site’s capacity to handle heavy traffic increases, and your risk of site failure goes down.
Prepare for heavy traffic. Load test your site.
Load test your site with thousands of Browser Bots, using real Chrome browsers. Fix bottlenecks. Prevent crashes.
Get 50 units of free Loadster Fuel to power your first few cloud tests.
Start Testing for Free Learn More